Page 1 · Deep models need representations
Page 2 · Language modelling + pretraining
![Page 2 of 4 — Language modelling + pretraining. Seven cards (10–16): (10) self-supervised learning, raw text provides the supervision signal, the model sees text, creates a task it can solve, and learns, examples: mask tokens ([MASK]) or predict next word/sentence, raw text → self-generated supervision with no labels needed; (11) pretrained models, models are trained once on huge corpora learning general language knowledge, capture grammar, facts, commonsense, and reasoning patterns, reusable starting point for classification, QA, NLI, summarization, one expensive pretraining run → many downstream uses, knowledge is reused not relearned; (12) repositories of pretrained models by language / domain, model hubs (Hugging Face Hub, TensorFlow Hub, PyTorch Hub) provide many ready-to-use checkpoints for English (BERT, RoBERTa, DeBERTa, DistilBERT, Llama, Mistral), domain-specific (BioMedLM, SciBERT, ClinicalBERT), multilingual (mBERT, XLM-R, LaBSE, XLM-T), pick a model that matches your language and domain; (13) transfer learning, take a pretrained model and adapt it to your target task/domain, pipeline: pretrained model (general LM) → task adaptation (fine-tune or feature extract) → task classifier, start from learned knowledge, update only a small part (or all) with task data, leverage broad knowledge → learn the specifics, dramatically reduces labeled-data needs; (14) fine-tuning, continue training the model on your target task, updates the model weights using task-specific labeled data, before fine-tuning general pretrained model → fine-tune on task data (labels) → after fine-tuning task-specific model, WARNING: update weights not just the head, small data big gains; (15) tiny labelled dataset after pretraining, fine-tuning works with much less data than training from scratch, typical accuracy vs labeled data plot shows pretrained + fine-tuned reaching 90%+ with 10^2 examples while from-scratch requires 10^5+, pretraining + fine-tuning needs far less data, huge reduction in labeled data; (16) fine-tuned representation + simple classifier, use the fine-tuned model to produce rich representations then a small classifier head for the task, input text → pretrained/fine-tuned encoder (Transformer) → representation (sentence embedding) → simple classifier head (Linear) → label (Positive), why this works: encoder learns general language, task head learns the decision, few parameters to train, fast/efficient/effective. Takeaway: self-supervised learning turns raw text into supervision at scale, pretrained models are reusable checkpoints of knowledge, transfer learning + fine-tuning solve most of the annotation bottleneck.](/_next/image?url=%2Fimages%2Fblog%2Fnlp-from-scratch%2Ftext-classification%2Fcheatsheet%2Fpart-7-page-2-pretraining.png&w=3840&q=75)
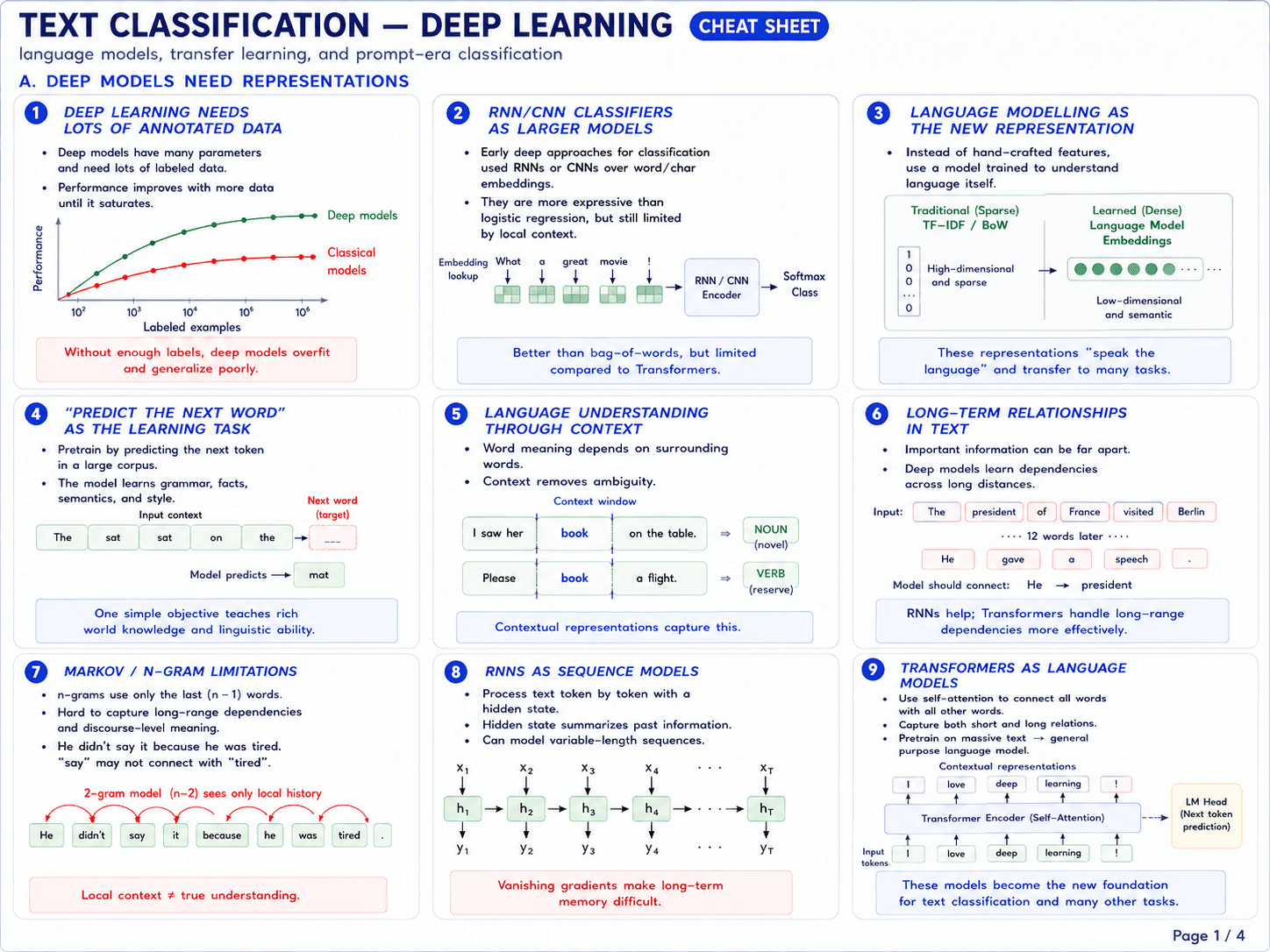
Page 3 · Fine-tuning + representation reuse
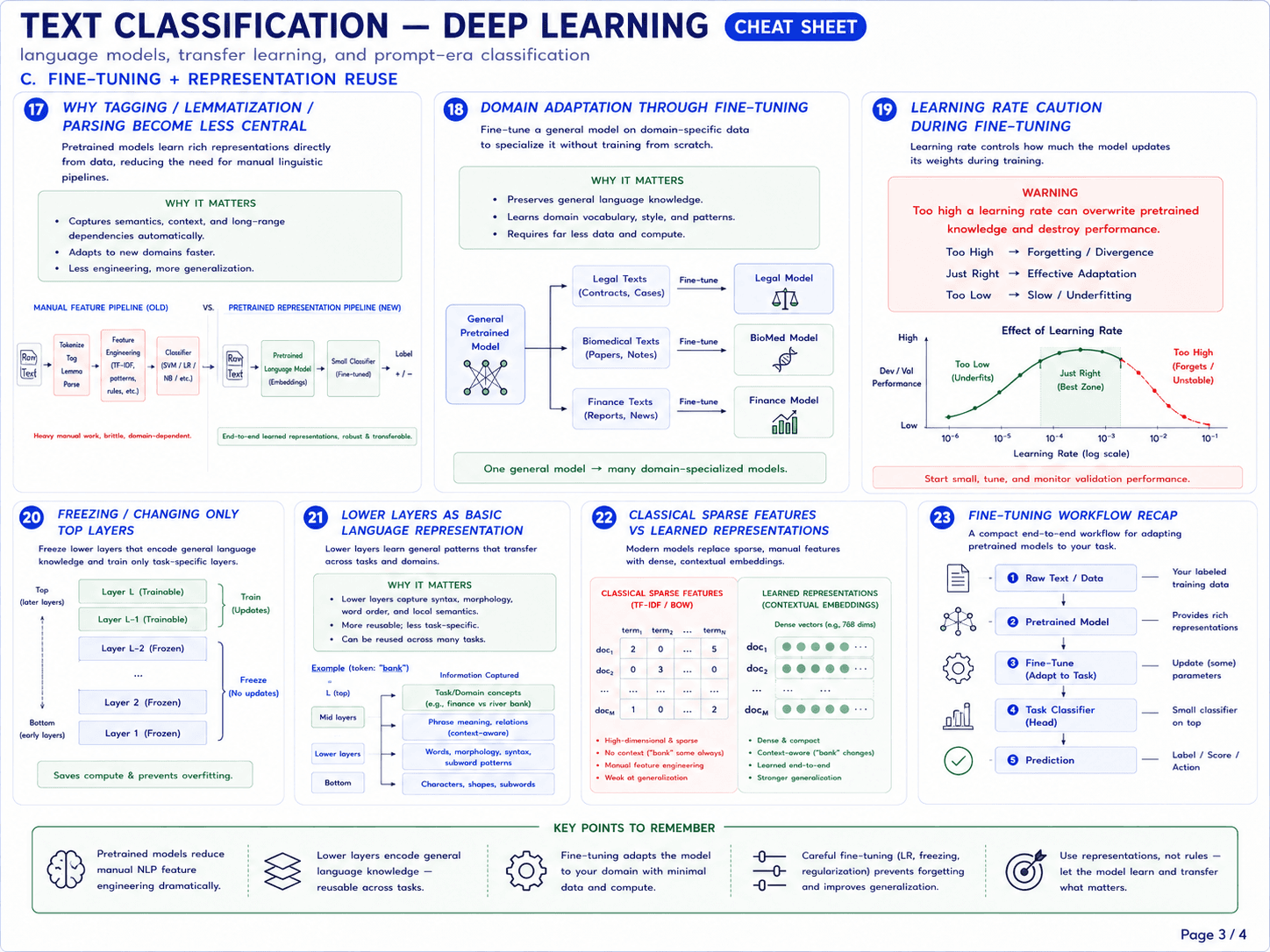
Page 4 · Zero-shot, few-shot + prompt era
Cheat sheet
Four illustrated pages — deep representations, language modelling and pretraining, transfer learning and fine-tuning, and the zero-shot / prompt era.

Or read the searchable version below.