
Table of Contents
- 1. Why this guide exists
- 2. The task in one picture
- 3. The RL vocabulary in this context
- 4. What the agent maximizes
- 5. Policy: the agent’s “brain”
- 6. Actor–Critic: two networks, one team
- 7. PPO’s stability trick
- 8. One-step view of the loop (lander edition)
- 9. Hyperparameters (plain English)
- 10. A minimal mental model of training
- 11. What to watch in your logs
- 12. Tips if you train it yourself
- 13. Takeaway
Last update: February 2025. All opinions are my own.
Why this guide exists
This post is a clearer, longer adaptation of the PPO visual guide: short equations plus plain-English translations, so someone new to RL can follow what you built.
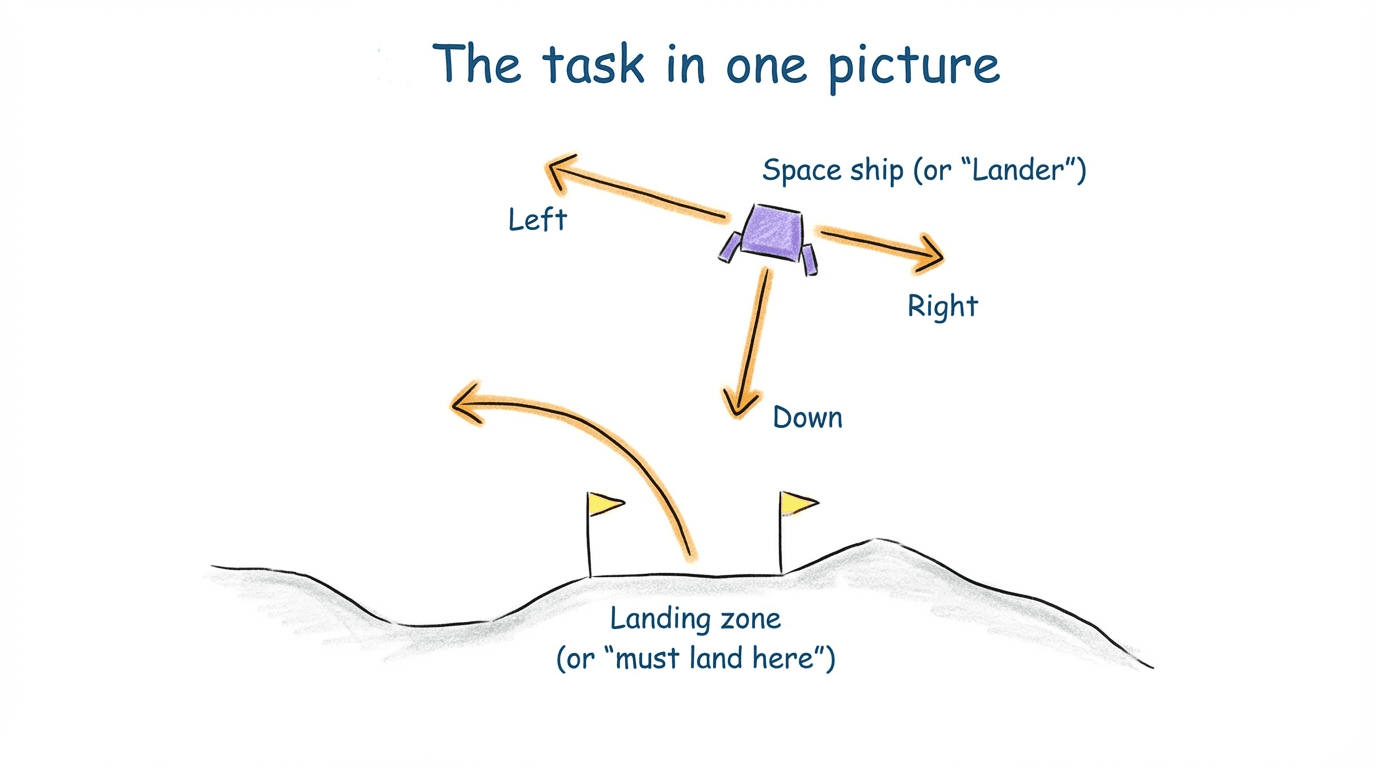
The task in one picture
LunarLander is a small simulation with four discrete actions: fire left engine, fire right engine, fire main engine, or do nothing. The goal: touch down gently between two flags without crashing.
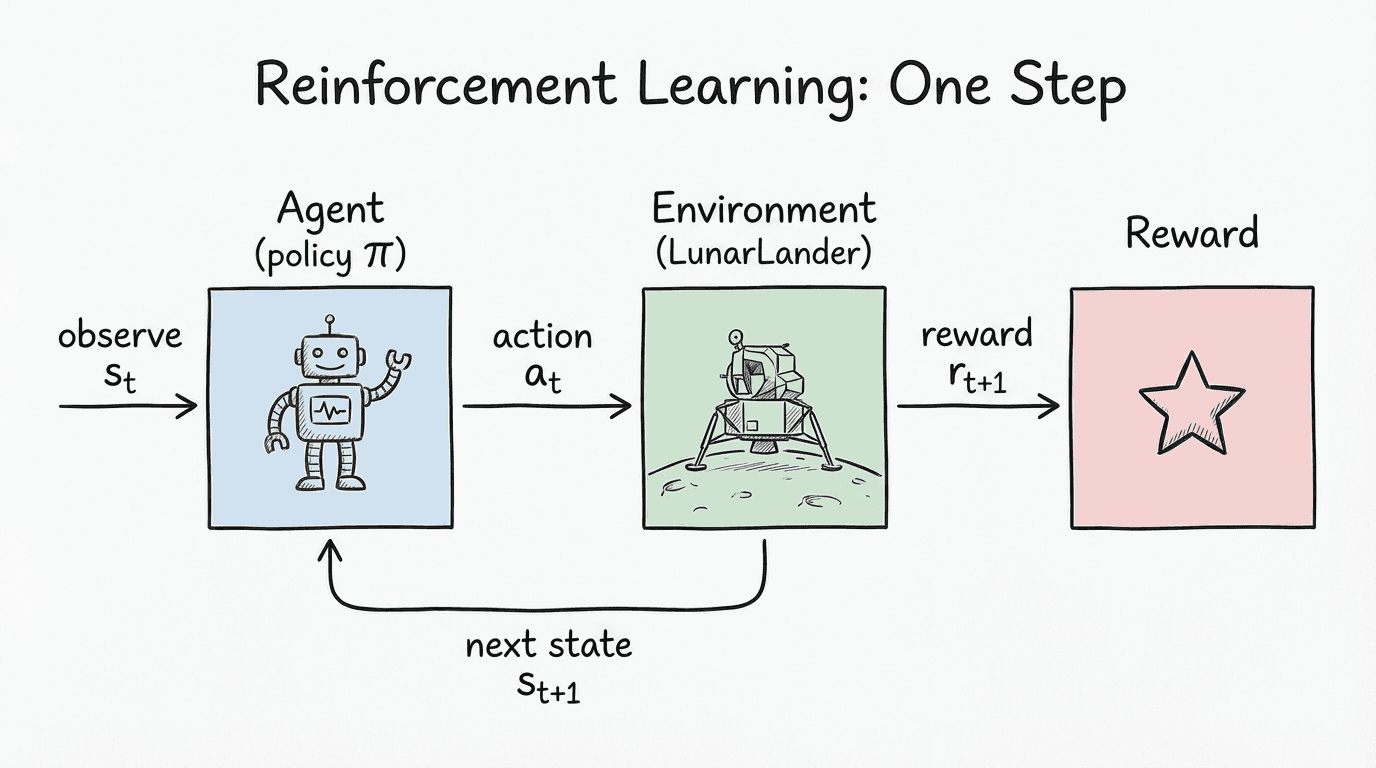
What this diagram shows: At each timestep, the agent (lander) looks at the state, picks an action, receives a reward and a new state, and then tries again. The whole game is to keep repeating that loop until the sequence of actions leads to a soft landing between the flags.
The RL vocabulary in this context
- State
s_t: position, velocity, angle, leg contact signals. - Action
a_t: one of four thruster choices. - Reward
r_t: a number for that step (closer, softer, upright is better; crashes are bad). - Next state
s_{t+1}: what the lander senses after the action. - Value
V(s): critic’s guess of how much future reward is available from here.
Think: “what I see → what I do → what I get → what I see next.”
What the agent maximizes
We do not optimize accuracy; we optimize total discounted reward:
G = r₀ + γ·r₁ + γ²·r₂ + γ³·r₃ + …
γ close to 1 means the agent cares about a safe landing later, not just quick points now.
How the reward is shaped here: small positives for being closer to the pad and upright, small negatives for drifting or tilting, a big negative for crashing or flying away. Shaping speeds up learning but still points at the true goal: a soft landing between the flags.
Policy: the agent’s “brain”
π(a | s) = probability of taking action a in state s.
During training we adjust the policy so good actions become more likely.
Actor–Critic: two networks, one team
- Actor (policy): chooses the action.
- Critic (value): estimates how good the current state is (
V(s)). - Advantage
A(s,a): how much better (or worse) an action did than the critic expected. Positive advantage ⇒ do it more; negative ⇒ do it less.
PPO’s stability trick
Updating the policy too hard can collapse learning. PPO measures how the new policy differs from the old one for the same action in the same state:
r_t = π_new(a_t|s_t) / π_old(a_t|s_t)
Then it clips that ratio to stay within [1 − ε, 1 + ε]. This keeps updates safe while still improving.
One-step view of the loop (lander edition)
Already shown above: the agent acts, the environment responds with reward and the next state; the policy updates and tries again.
Hyperparameters (plain English)
| Hyperparameter | What it controls | Intuition | Example |
|---|---|---|---|
| Learning rate (actor/critic) | Update size | Bigger steps learn faster but can break training | 0.001 / 0.001 |
Gamma γ | Future reward weight | Close to 1 = long-term planning (safe landing) | 0.99 |
Lambda λ (GAE) | Advantage smoothing | Reduces noisy signals | 0.9 |
| Entropy coef | Exploration strength | Encourages trying different actions early | 0.2 |
Clip ε | Max policy change | Prevents giant updates; keeps PPO stable | 0.4 (0.1–0.3 common) |
A minimal mental model of training
- Roll out episodes with the current policy; collect states, actions, rewards.
- Use the critic to compute advantages (
A = actual – expected). - Update the policy with PPO’s clipped objective so good surprises get reinforced without wild shifts.
- Rinse and repeat until the reward curve flattens near “soft, centered landings.”
What to watch in your logs
- Episode reward: rising toward smooth landings.
- Value loss: should trend down; spikes can signal critic instability.
- Entropy: should decrease over time as the policy commits to good actions.
- Clip fraction: how often PPO hits the clip boundary; very high → learning could be throttled, very low → maybe increase steps/entropy.
Tips if you train it yourself
- Start in simulation; failure is cheap.
- Shape rewards carefully (distance, angle, speed penalties) but keep the main goal aligned with landing softly.
- Decay exploration (entropy) gradually.
- If it oscillates, lower learning rates or the clip epsilon.
- For visuals, save a short GIF of a successful landing; it pairs well with the diagrams above.
Takeaway
PPO works for LunarLander because it improves steadily without letting the policy swing wildly. By combining actor–critic estimates with clipped updates, the agent learns the sequence of thruster nudges that bring the craft down between the flags—no labeled dataset required.